[코딩테스트 합격자 되기 04] 코딩 테스트 필수 문법
빌트인 데이터 타입
정수형 :
양의 정수, 음의 정수, 0
사칙연산(+ ,- ,* ,/) 외 많은 연산(비교연산, 비트연산, 논리연산 등) 가능
print(a / b) # 나누기 (소수점 포함) / 3.25
print(a // b) # 나누기 (소수점 제외) / 3
부동소수형 :
소수를 저장할 때 사용. 사칙연산과 정수형 나누기, 모듈러(%), 제곱 연산(**), 논리 연산 등 가능
print(10.0 // 3.2) # 정수형 나누기 / 3.0
print(10.0 % 3.2) # 모듈러 / 0.39999999999999947
print(2.0 ** 3.2) # 제곱 연산 / 9.18958683997628
부동소수형 코드 실행 결과를 보면 10 % 3.2의 연산 결과를 보면 결괏값이 0.4가 아니라 0.39999999999999947 인 것이 눈에 띈다.
앱실론을 포함한 연산에 주의하라
이런 이유는 파이썬은 부동소수형 데이터를 이진법으로 포현하기 때문이다. 소수점 연산은 정확한 연산을 할 수 없어 근삿값으로 대체된다. 표현 과정에서 오차가 발생하는 것인데, 파이썬에서는 아래와 같이 엡실론을 이용해 해결한다.
엡실론 이용
부동소수점으로 실수를 표현하면 소숫점 이하가 무한히 반복되기 때문에 특정 시점에 반올림하여 실제 값과 비슷한 근삿값을 구하게 된다. 이렇게 실제 값과 근삿값 사이에 발생하는 오차를 반올림 오차 라고 하는데, 이 차이는 항상 머신 엡실론 값 보다 작다.
이와 같은 특성을 이용하여 실수 비교를 수행한다. 근삿값에서 실제 값을 뺀 값이 머신 엡실론 보다 작다면, 이는 같은 값으로 취급하면 된다.
머신 엡실론 값은 sys.float_info.epsilon 에 저장되어 있다.
import sys
# 엡실론 출력
print(sys.float_info.epsilon) # 2.220446049250313e-16
# 부동소수점 수의 오차 검사
a = 0.1 + 0.1 + 0.1
b = 0.3
print(a - b) # 5.551115123125783e-17
if abs(a - b) < sys.float_info.epsilon:
print("a와 b는 같은 값입니다.") # 이 코드가 출력됨
else:
print("a와 b는 다른 값입니다.")
따라서 부동소수형을 사용하여 코드를 작성하면 엡실론이라는 요소 때문에 일부 테스트 케이스가 통과하지 못할 수도 있으니 코딩테스트에서 부동소수형 데이터를 다룰 일이 생겼을 때에는 엡실론을 항상 생각하는 것이 좋다.
컬렉션 데이터 타입
컬렉션은 여러 값을 담는 데이터 타입을 말한다. 대표적으로 리스트, 튜플, 딕셔너리, 셋 , 문자열 등이 있다. 이 컬렉션들은 데이터의 수정 가능 여부에 따라 변경할 수 있는 객체와 변경할 수 없는 객체 두 가지로 구분한다. 변경할 수 있는 객체는 뮤터블 객체, 변경할 수 없는 객체는 이뮤터블 객체라고 부른다.
뮤터블 객체
뮤터블 객체는 객체 생성 수 객체를 수정할 수 있다. 대표적인 뮤터블 객체는 리스트, 딕셔너리, 셋 이다.
my_list = [1, 2, 3, 4, 5] # 리스트 객체 생성, [1, 2, 3, 4, 5]
my_list[4] = 6 # 리스트 원소 변경
print(my_list) # [1, 2, 3, 4, 6]위 코드는 다음과 같이 동작한다.

이뮤터블 객체
이뮤터블 객체는 객체 생성 후 객체를 수정할 수 없다. 대표적인 이뮤터블 객체는 튜플, 정수, 부동소수점, 문자열이다. (정수가 컬렉션 데이터 타입에 포함되는 것은 아니다)
a = 4 # ➊ a = 4
b = a # ➋ a = 4, b = 4 / b는 a가 아닌 a가 참조한 4를 참조
b += 2 # ➌ b = 6 / 기존에 참조한 객체를 수정하지 않음, 새 객체 6을 참조
print(a, b) # 4 6
➊ a가 4라는 객체를 참조한다.

➋ a가 참조한 4라는 이뮤터블 객체를 b도 똑같이 참조한다.

➌에 의해 b는 6이라는 객체를 참조한다. 주목할 점은 4는 이뮤터블 객체이므로 수정할 수 없다. 따라서 객체 6을 새로 생성하고 그 객체를 참조한다.

리스트
리스트는 뮤터블 객체이며 흔히 '시퀀스(순서) 가 있는 자료형'이라 말한다. 이런 특징으로 리스트는 인덱싱, 슬라이싱을 할 수 있다.
리스트 인덱싱
인덱싱은 인덱스를 활용해서 특정 위치의 원소에 접근하는 것을 말한다. 예를 들어 my_list[2] 처럼 대괄호를 통해 원소에 접근하는 것을 인덱싱으로 원소에 접근한다. 라고 표현한다. 인덱스는 0부터 시작하며 음수를 통한 인덱스 접근도 가능하다(역순)
리스트 슬라이싱
슬라이싱은 시퀀스 자료형의 범위를 지정해서 값들을 복사하여 가져오는 방식이다. 슬라이싱은 파이썬 코드로 list_name[a:b]와 같이 작성한다.
딕셔너리
파이썬의 딕셔너리dictionary는 뮤터블 객체이며, 키key와 값value 쌍을 저장하는 해시 테이블로 구현되어 있다.
먼저 딕셔너리 하나를 선언하는 방법은 이렇다.
my_dict = { }
딕셔너리에 값을 삽입하고 딕셔너리 전체를 출력하는 코드이다.
# 딕셔너리 값 삽입
my_dict["apple"] = 1
my_dict["banana"] = 2
my_dict["orange"] = 3
# 딕셔너리 값 출력
print(my_dict) # {'apple': 1, 'banana': 2, 'orange': 3}
딕셔너리 검색
my_dict가 참조하는 딕셔너리의 키들을 보며 “apple” 문자열이 일치하는지 확인하고, 일치하는 키를 찾으면 키-값을 출력한다.
key = "apple"
if key in my_dict:
value = my_dict[key]
print(f"{key}: {value}") # apple: 1
else:
print(f"{key}는 딕셔너리에 존재하지 않습니다.")
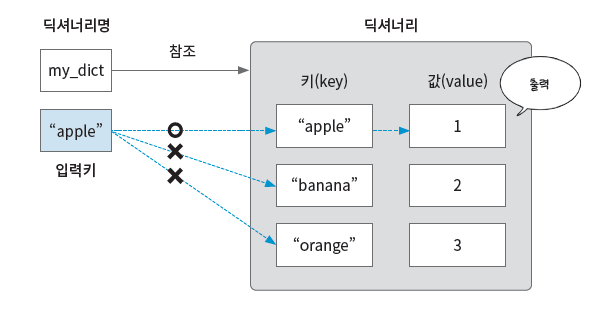
딕셔너리는 해시를 이용해 바로 키값을 검색할 수 있지만, * for문을 이용하여 딕셔너리를 차례대로 탐색하는 경우 에러 처리를 할 수 있어 유용하다
딕셔너리 수정
키 “banana”를 검색하여 해당 키의 값을 4로 바꾼다. 딕셔너리 내부는 해시 테이블로 구성되어 있으므로 해시 테이블에서 키를 찾거나 하지 않아도 된다.
my_dict["banana"] = 4
print(my_dict) # {'apple': 1, 'banana': 4, 'orange': 3}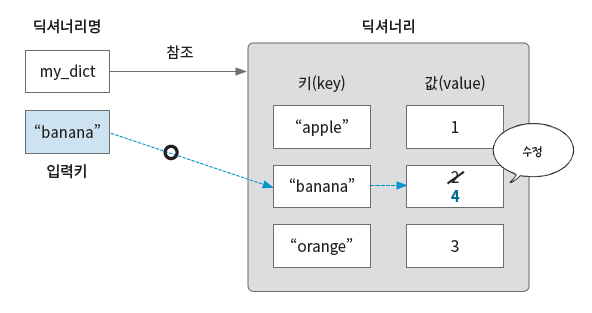
딕셔너리 삭제
키 “orange”를 찾아 딕셔너리에서 삭제한다.
del my_dict["orange"]
print(my_dict) # {'apple': 1, 'banana': 4}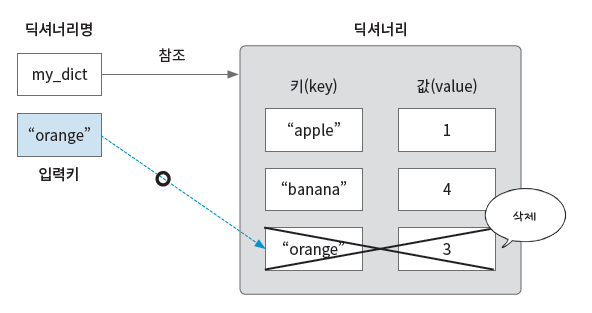
아래는 딕셔너리에 키가 없는 경우를 처리하는 예외 처리이다 (딕셔너리 검색 예시에서 처럼 in을 이용하여 for 문과 같은 방식으로 탐색)
# ➊ 딕셔너리 생성
my_dict = {"apple": 1, "banana": 2, "cherry": 3}
# ➋ my_dict에 없는 key로 설정
key = "kiwi"
# ➌ 키가 딕셔너리에 있는지 확인
if key in my_dict:
# ➍ 키가 딕셔너리에 있으면 해당 값 출력
print(f"값: {my_dict[key]}")
else:
# ➎ 키가 딕셔너리에 없으면 에러 메시지 출력
print(f"'{key}' 키가 딕셔너리에 없습니다.")
튜플
튜플은 이뮤터블 객체. 앞서 살펴본 리스트, 딕셔너리와 달리 한 번 생성하면 삽입하거나 삭제할 수 없다.
튜플은 다음과 같이 초기화한다.
my_tuple = (1, 2, 3)
튜플 인덱싱, 슬라이싱
삽입, 삭제는 되지 않지만 인덱싱, 슬라이싱은 할 수 있다. 문법 자체는 리스트와 같다.
my_tuple = (1, 2, 3)
# 인덱싱
print(my_tuple[0]) # 1
print(my_tuple[1]) # 2
print(my_tuple[2]) # 3
# 슬라이싱
print(my_tuple[1:]) # (2, 3)
print(my_tuple[:2]) # (1, 2)
print(my_tuple[1:2]) # (2,)
문자열
문자열은 문자들을 집합의 형태로 구성한 이뮤터블 객체이다.
string = "Hello, World!" # 큰따옴표 사용
string2 = 'Hello, World!' # 작은따옴표 사용
문자열 추가, 삭제
다음은 문자열을 추가하고 삭제하는 동작이다. 여기서 주목해야 할 점은 문자열은 이뮤터블 객체이므로 기존 객체를 수정하는 것이 아니라, 새로운 객체를 반환한다는 사실이다.
string = "He" # ➊
string += "llo" # ➋
print(string) # "Hello"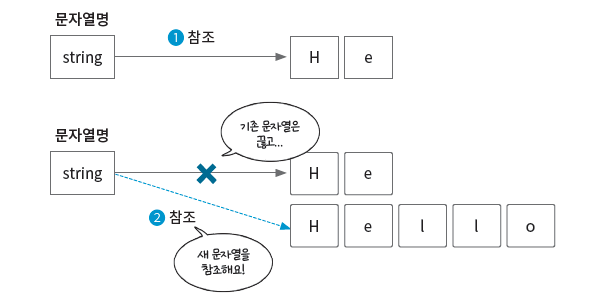
문자열 수정
replace() 메서드를 이용하면 문자열을 수정할 수 있다. replace( ) 메서드는 첫 번째 인수에 찾을 문자열을, 두 번째 인수에 변경할 문자열을 넣어 사용한다. 예를 들어 replace(A, B)는 replace( ) 메서드의 대상 문자열에서 A를 모두 찾아 B로 변경한다.
string = "Hello"
string = string.replace("l", "") # "l"을 모두 삭제
print(string) # Heo
함수
람다식
파이썬은 람다식을 사용할 수 있다. 람다식은 함수를 더 간단하게 표현하는 방법이며 다음과 같이 정의한다.
lambda x, y : x + y # x와 y를 받아서 더한 값을 반환하는 람다식
코딩테스트 구현 노하우
조기 반환
코드 실행 과정이 함수 끝까지 도달하기 전에 반환하는 기법 (예외 처리시 조금 더 빠르게 처리)
def total_price(quantity, price):
total = quantity * price # ➊
if total > 100: # ➋ total이 100보다 크면
return total * 0.9 # ➌ 조기 반환
return total
print(total_price(4, 50))
보호 구문
본격적인 로직을 진행하기 전 예외 처리 코드를 추가
def calculate_average(numbers):
if numbers is None: # ➊ 값이 없으면 종료(예외)
return None
if not isinstance(numbers, list): # ➋ numbers가 리스트가 아니면 종료(예외)
return None
if len(numbers) == 0: # ➌ numbers의 길이가 0이면 종료(예외)
return None
total = sum(numbers) # ➍
average = total / len(numbers)
return average
합성 함수
def add_three(x): # ➊
return x + 3
def square(x): # ➋
return x * x
composed_function = lambda x: square(add_three(x)) # ➌
print(composed_function(3)) # ➍ (3 + 3)^2 = 36ref :
04 코딩 테스트 필수 문법
# 공부부터 합격까지 코딩 테스트 문제를 풀기 전에는 당연히 코딩 테스트에 사용할 언어의 문법을 알아야 합니다. 여기서는 파이썬 기초 문법을 충실히 설명하기보다는 코딩 테스트에…
wikidocs.net
https://itholic.github.io/python-floating-point/
[python] 파이썬에서 부동소수점 다루는법
부동소수점 처리
itholic.github.io